Animate In
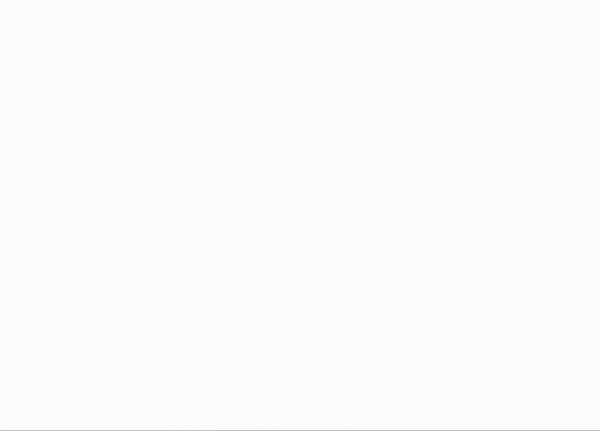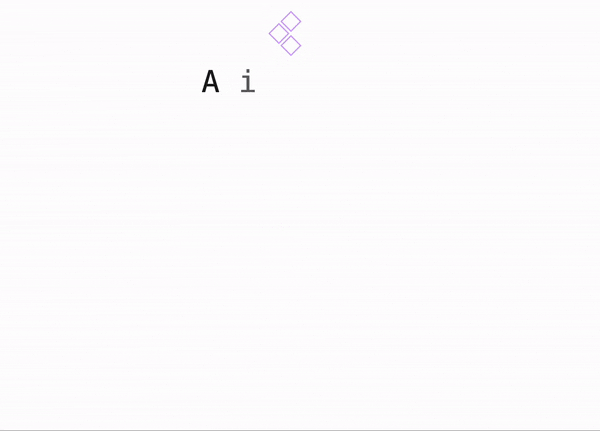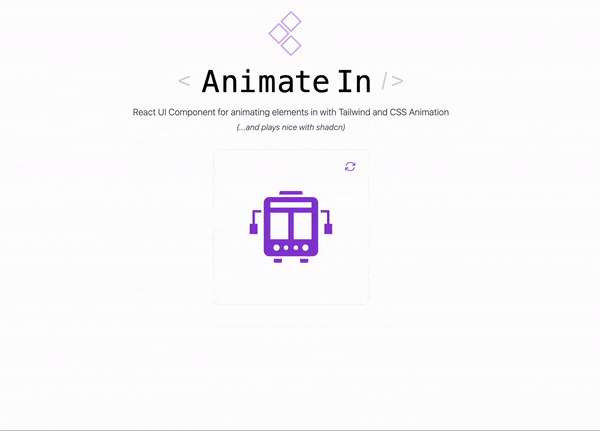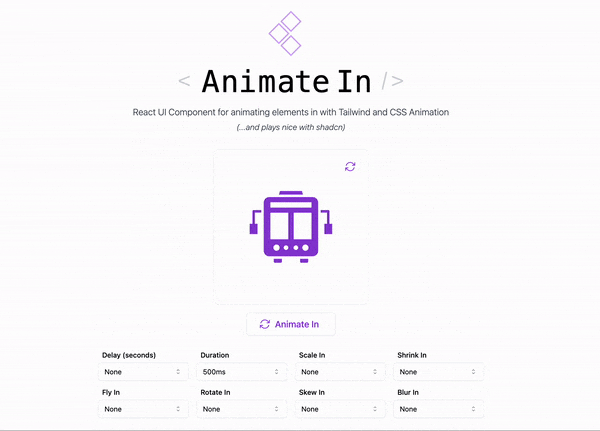
Introduction < AnimateIn /> a re-usable React component that I’ve made to drop in whenever I want to quickly add some animation effects to my projects
Websites that Create Themselves

I built Not Yet News to experiment with creating a website that generates its own content.
Making Components with shadcn
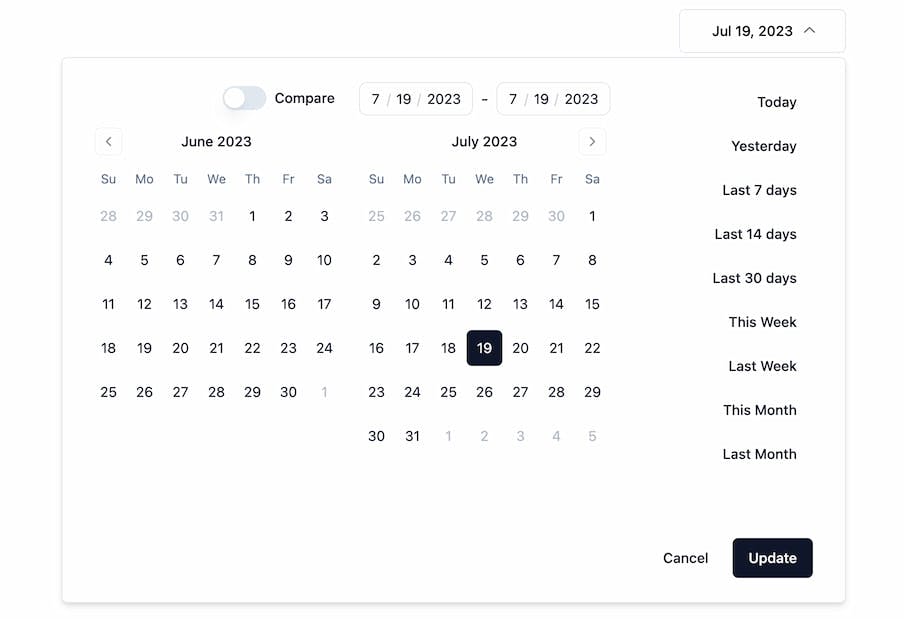
I built a DateRangePicker component for shadcn and open sourced it on Github.


Playing with the Open AI API

I used the ChatGPT API to create BotLuck, a fun themed recipe generator.